ビッグデータから
「機会獲得に有用な情報」を発掘する
大量の情報(ビッグデータ)があふれる現代社会では、AI(Artificial Intelligence)など関連技術の飛躍的な進歩と相まって、企業競争力強化に向けた経営やマーケティングの精度向上のためにビッグデータを活用することへの期待が高まっています。電通では、ビッグデータ分析を通じて「機会獲得に有用な情報」を発掘し、経営やマーケティングの意思決定に活用できる仕組みを構築することをDXの目的と捉え、電通グループ/提携企業各社と共にさまざまなメソドロジーやソリューションの開発に取り組んでいます。
ここでいう機会獲得に有用な情報は、「現在獲得できていない機会」「機会獲得のための課題」「課題解決のための仮説」「仮説検証から得られる教訓」の4つの情報に大別できます。これらの課題解決プロセスに含まれる4つの情報が充実し、事業を取り巻く環境の解像度を高めることができれば、経営やマーケティングにおけるさまざまな意思決定の精度が改善され、より確実な機会獲得が期待できます。
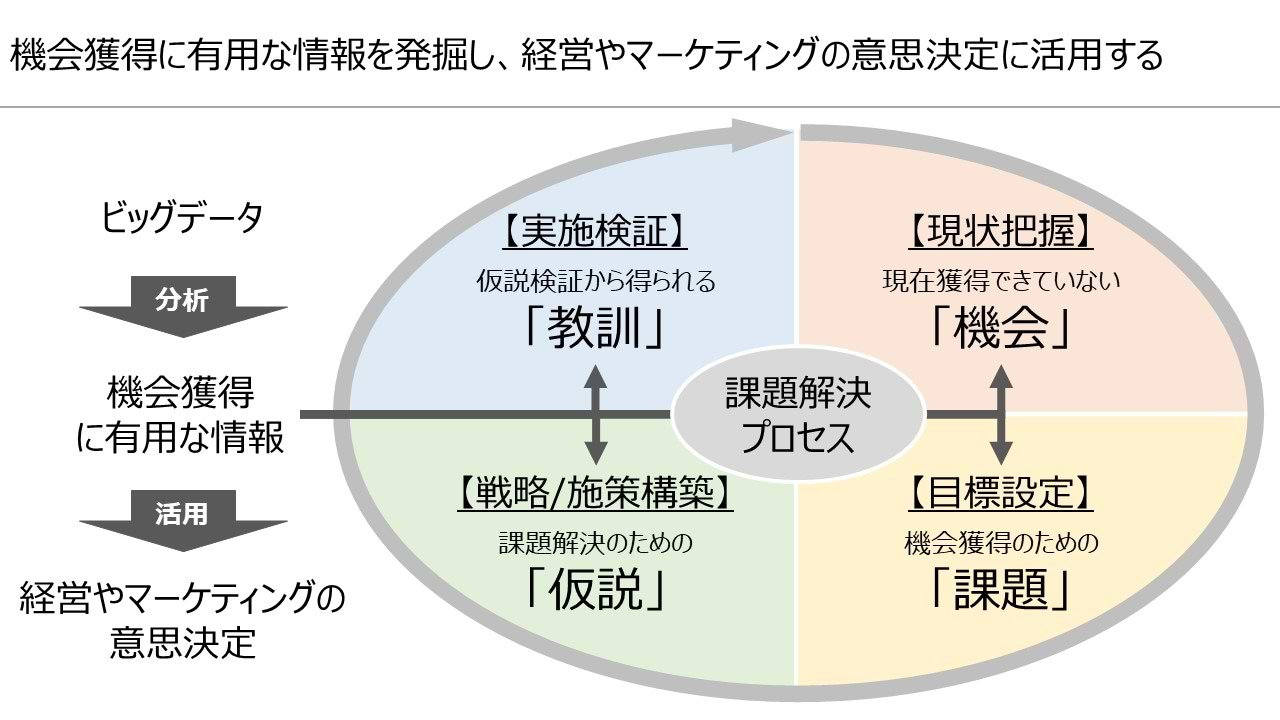
機会獲得に有用な情報の発掘を可能にする
「顧客起点の事業分析」
例えば同じ100個の売上でも、1人が100個買っている場合と100人が1個ずつ買っている場合では、そのブランドが抱える課題は大きく異なります。前者は認知に、後者は満足度に課題がある可能性があるわけですが、この課題を正確に捉えることができないまま戦略/施策を実行すると、獲得できる機会は限定的なものになります。また過去実施した戦略/施策のどのような要素がターゲット顧客の(認知/購買/満足などの)意識/行動変容に有効なのかといった教訓を生かさずにその後の戦略/施策を実行すると、獲得できる機会はやはり限定的なものになります。
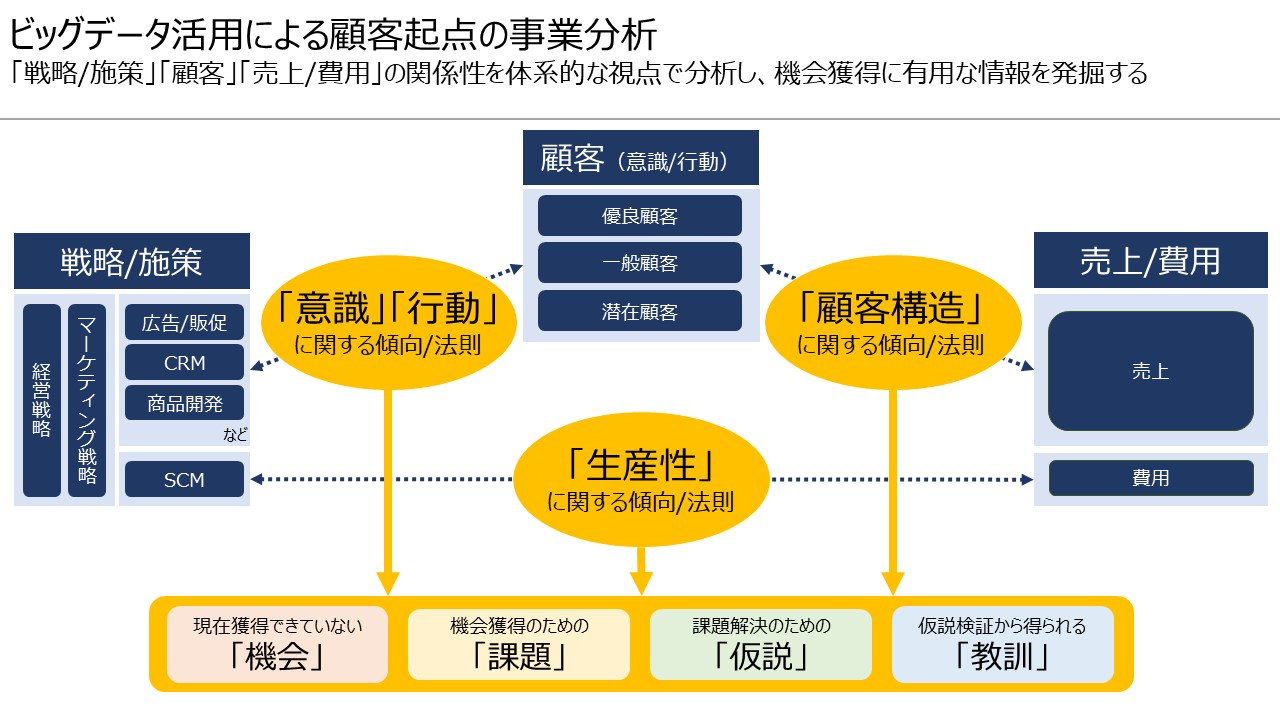
このように機会獲得に有用な情報を見逃すことは機会損失の原因となるため可能な限り発掘することが望ましいわけですが、そのために電通では「戦略/施策」「顧客(意識/行動)」「売上/費用」の関係性を明らかにする「顧客起点の事業分析」を推奨しています。ビッグデータ分析を通じて「戦略/施策(を構成する各要素)が顧客の意識/行動に与える影響」「顧客構造の変化が売上に与える影響」「戦略/施策が生産性に与える影響」に関する傾向/法則を抽出し、さらに体系的な視点で分析を行うことで機会/課題/仮説/教訓を発掘します。そしてこれらの情報を広告/販促やCRM(Customer Relationship Management)はもちろん、商品開発やサプライチェーンマネジメント(SCM)などの経営やマーケティングにおけるさまざまな意思決定の場面で活用することで、より多くの機会獲得が可能となります。
意思決定を正解へと近づける予測/最適化
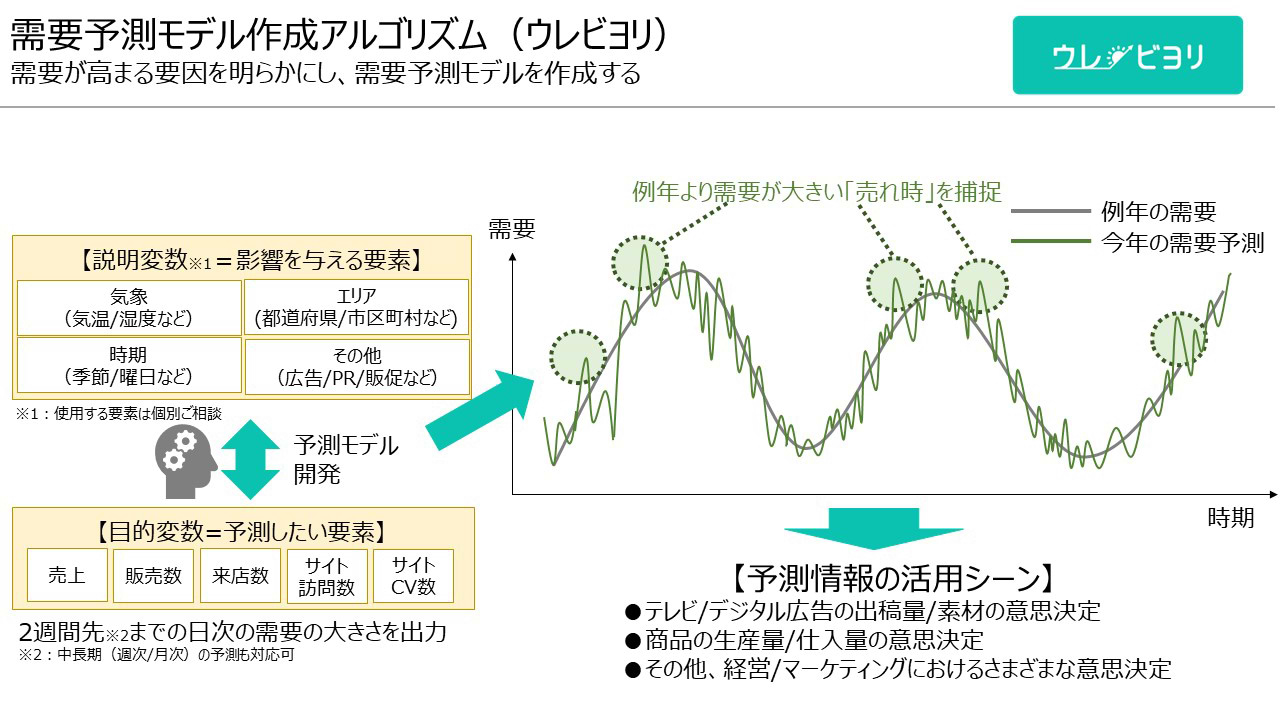
広告は本来、需要が高まるタイミングに当てることが理想とされています。夏にスポーツドリンク、冬にホットコーヒーの広告がシーズナルに展開されるのはそのセオリーに則しているからですが、現在では品目によってはビッグデータを活用することで需要の高まる条件を市区町村や日次といったより細かい粒度で把握することが可能となり、そこから得られた教訓をマーケティングの精度改善に活用するニーズが高まりつつあります。電通では気象データなどのコーザルデータを用いた独自の需要予測モデル作成アルゴリズム(ウレビヨリ)と、予測情報を含むビッグデータとAIを活用したマーケティングメソドロジー(ミチシロウ)を開発。これらのアルゴリズムやメソドロジーを活用した施策展開を通じて、新たな機会獲得を支援させていただいています。
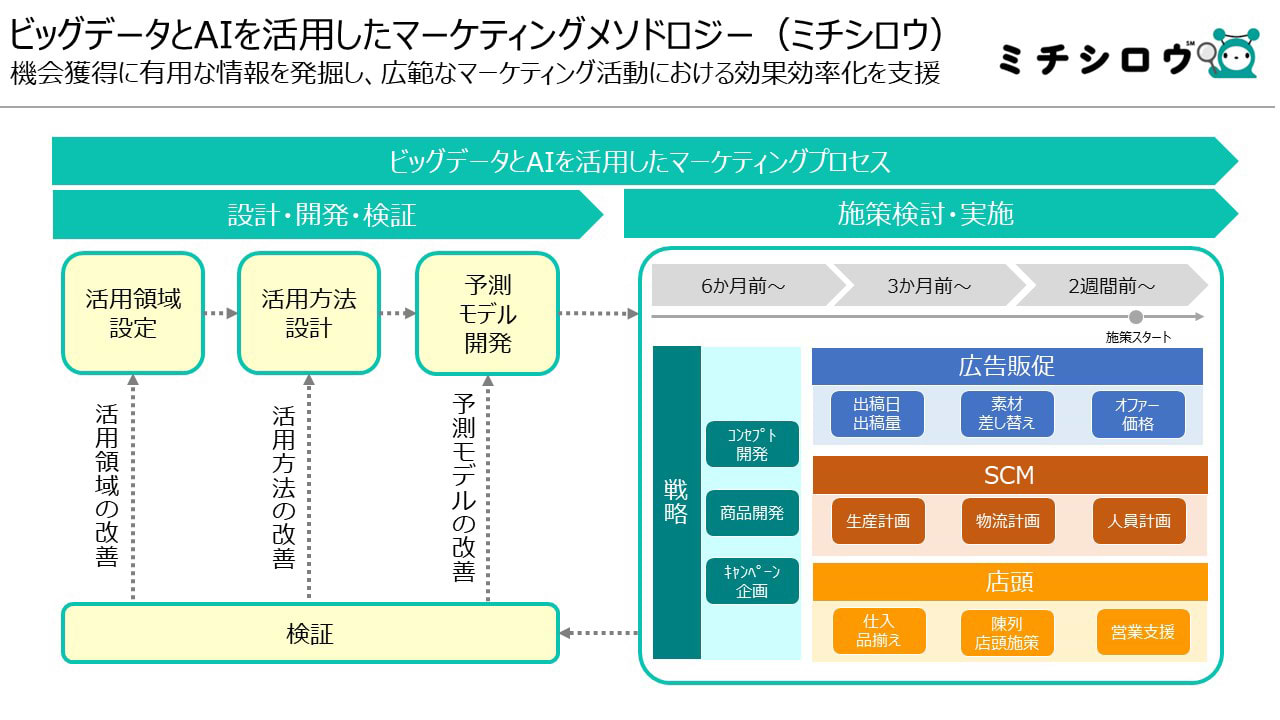
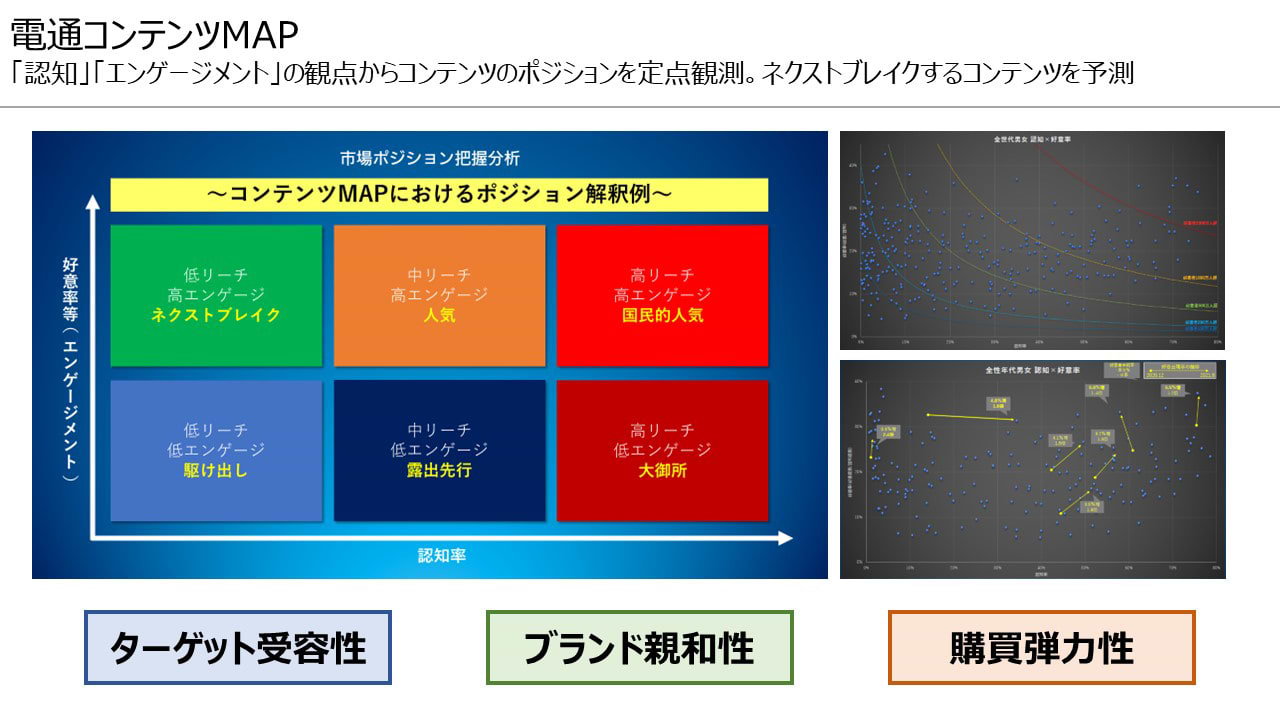
最近では予測対象も広がりを見せています。例えば、電通では「認知」「エンゲージメント」の尺度を用いてコンテンツのポジションを定点観測し、その時系列変化の傾向から次に流行ると思われる(ネクストブレイク)コンテンツを予測するデータベースを保有しています。「ターゲット受容性」「形成したいブランドイメージとの親和性」「購買に対する弾力性」などといったデータも整備していますので、マーケティング目的に立脚したプランニングを可能にします。タイアップコンテンツの選定や番組ゲストのキャスティングなどにも活用し、より高いマーケティング効果の創出に役立てています。
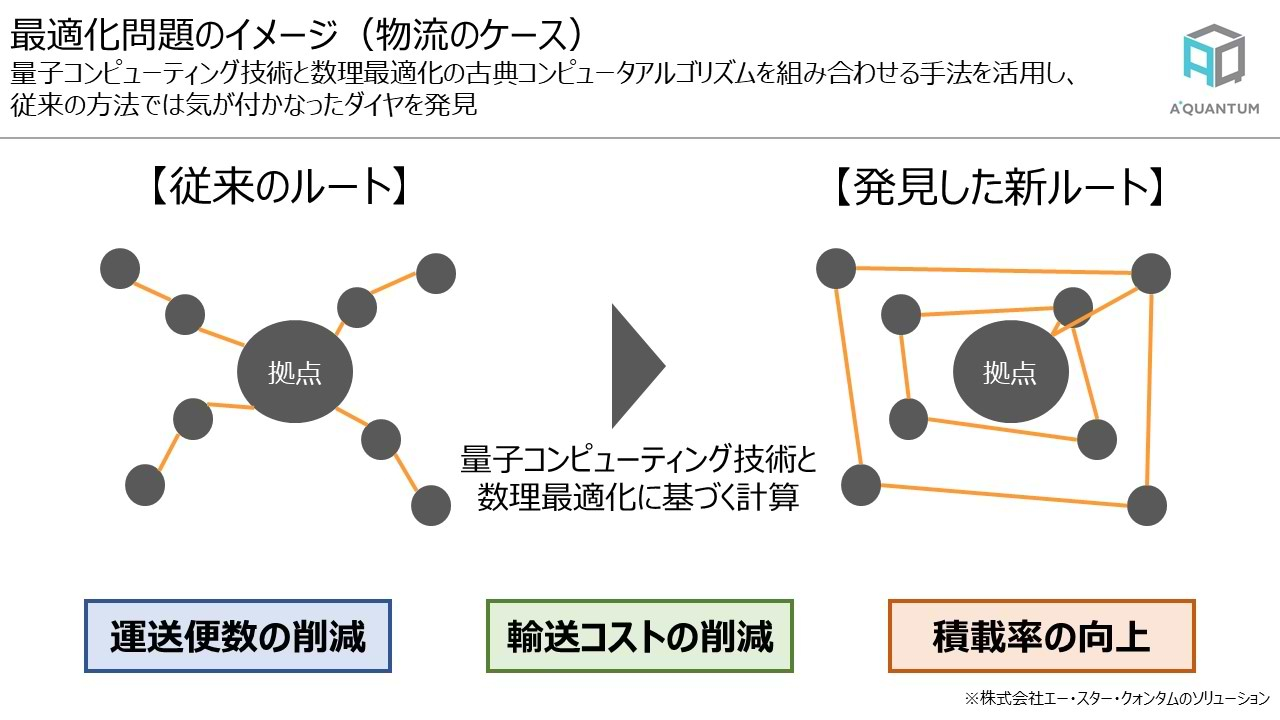
そして予測と同様に機会獲得に有用な情報として注目されているのが、物流の配送ルートなどに応用される最適化問題です。例えば、トラックの便数/稼働時間/荷積場所と時間/荷下場所と時間などの制約条件を前提に、最も効率的な配送パターンを導き出します。営業担当者の訪問先の順序/組み合わせや従業員やアルバイトのシフトなども最適化問題として取り扱います。これら最適化問題の共通点は、従来の方法では発見することができなかった意外性のある順列/組み合わせのパターンを最適化計算やソフトウェアのアルゴリズムによって可能にする点にあります。最適化問題を解く場合、基本的に考えられる全ての順列/組み合わせのパターンを計算し目的変数に対して最も効果的なパターンを見つけにいくことになるわけですが、これまでの計算機技術では内容によっては天文学的数字の時間を要することになり実用的ではありませんでした。ところが最近急速に進歩しているアルゴリズムや最適化の数式、そして量子コンピューティング技術を用いることで最適化問題を短時間で解くことが可能となり、今後解決される問題がますます増えることが期待されています。
ビッグデータ×AIの価値を引き出す「仕組み」の構築
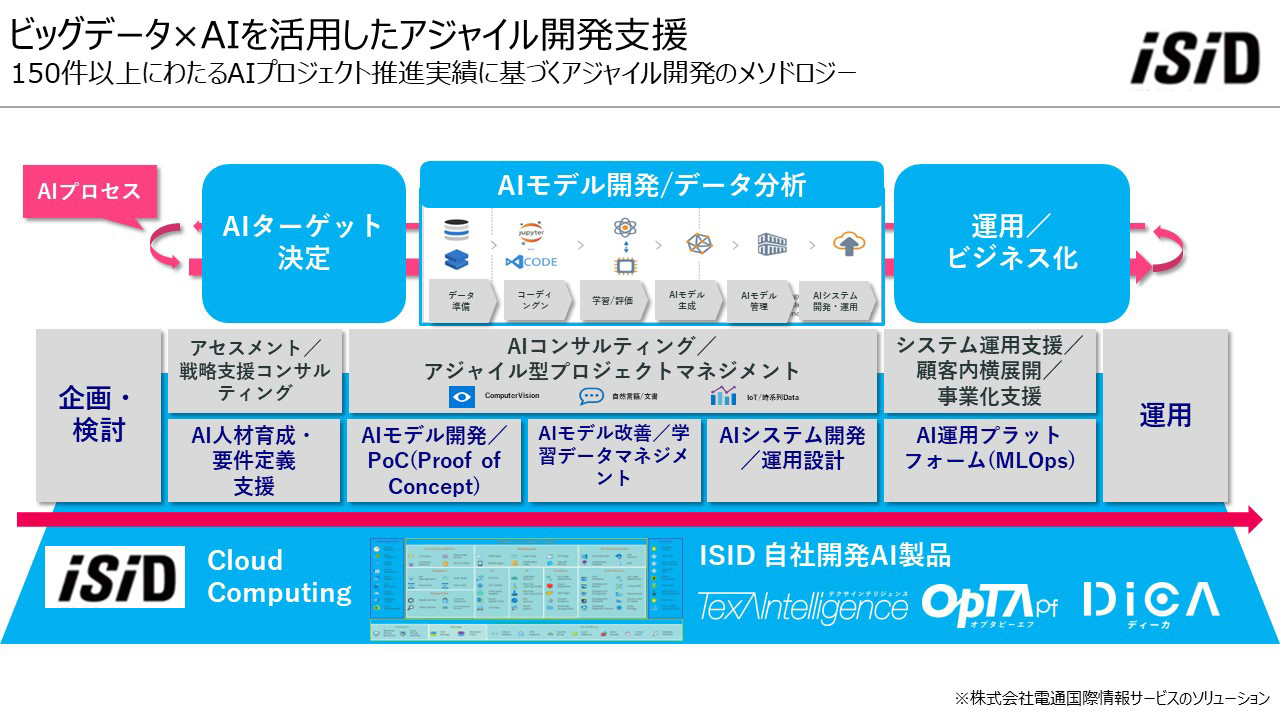
ビッグデータの価値を最大限に享受するには、経営から現場までのさまざまなレイヤー/部門で機会獲得に有用な情報を発掘し、それぞれの垣根を越えて必要なところへ共有/活用する仕組みの構築が必要となります。この仕組みの構築は、ビッグデータ活用に関する戦略企画にはじまり業務オペレーションの設計やその実行を支えるAIシステムの開発、さらに浸透/定着のための人材育成や意識改革など、幅広い領域において戦略的な対応が求められます。また、企業のAIに対する期待は高まりつつある一方で不確実性を伴うことから、電通グループの電通国際情報サービスでは、従来のウォーターフォール型ではなく、不確実性に向き合い試行錯誤を繰り返しながら探索的段階的に改良を重ねるアジャイル開発のためのメソドロジーを確立しています。このような全社的な取り組みを、戦略企画/設計からアジャイル開発、そして浸透/定着までを分離させることなく全体最適視点で推進できるケイパビリティは、電通グループならではの特長であると考えています。
ビッグデータ活用によって獲得できる機会は着実に拡大しています。そしてそう遠くない未来には、ビッグデータから機会獲得に有用な情報を発掘し経営やマーケティングの意思決定に活用するといった「経営/マーケティングのマネジメント変革」のためのDXを実行できるかどうかが、これからの企業競争力のKey Success Factor(重要成功要因)になると考えています。
引き続き電通は電通グループ/提携企業各社と共に、この目的に立脚したDXのケイパビリティを拡充させ、クライアント企業様の経営やマーケティングのグロースに貢献してまいります。